1. 人材データ分析(ピープルアナリティクス)とは?
人材データ分析(ピープルアナリティクス)とは、採用、選抜、配置、育成といった人事領域のあらゆる意思決定や戦略立案を、主観や勘に頼るのではなく、収集された客観的データに基づいて行う手法のことです。
現在、企業は「人的資本経営」の実践フェーズへの転換が求められていますが、依然として多くの組織がデータの利活用に課題を抱えています。SHLがグローバルで行った調査では、自社の従業員のポテンシャルを明確に把握できていると回答した組織は、44%に過ぎません。ビジネス上の意思決定を行う際にタレントデータに依存している組織の割合は、61%で過去数年間変わらず停滞しています。経営環境が激しく変化する中、過去の経験則だけでは通用しないシーンが増えており、人事の世界においても、データを用いた「公平かつ客観的な意思決定」が、企業の競争力を左右する死活問題となっているのです。
2. 人材データ分析の主要な目的
分析を成功させるには、「何のために行うか」という目的意識を明確にすることが不可欠です。主な目的は以下の4つに整理されます。
- 人材要件の定義(コンピテンシー定義):特定の職務やポストで活躍する「高業績者(ハイパフォーマー)」の特徴を抽出し、再現性のある採用・配置基準を確立します。
- 人材の可視化(棚卸し):部署ごとにどのような適性を持つ人材がどれくらいいるのか、組織全体のポテンシャルを概観します。これは、未経験の職務への適性を探る際にも非常に有効です。
- 選考・選抜プロセスの妥当性検証:現在の合格基準や面接評価が、入社後の実際の活躍や昇進と正の相関を持っているかを振り返り、選考精度を向上させます。
- リテンション(定着)と能力開発:組織に定着しやすい人の傾向や、階層ごとの能力開発ニーズを特定し、効果的な育成施策や離職防止策を立案します。

3. 実践!人材データ分析のステップ
精度の高い分析結果を人事アクションに繋げるためには、以下の5つのプロセスを構造的に進める必要があります。
- 目的と対象の選定:解決したい課題(例:次世代リーダー選抜、組織の可視化と再配置、営業職の離職防止、など)を定め、分析対象となる集団を決定します。
- パフォーマンス指標(目的変数)の準備:予測したい「成果」を定義します。売上数字や業績評価のほか、表彰歴、行動評価、あるいはマネジャーであればチーム業績などが用いられます。
- 説明変数の準備:要因を特定するためのデータです。パーソナリティ(行動特性)や知的能力を測定するアセスメントデータ(例:OPQデータ)を準備します。
- 統計分析の実施と専門的解釈:データに基づき、目的に適した手法で相関や差を算出します。算出された数値は、組織の文脈や職務特性に照らして解釈することが求められます。
- 施策への適用とアクション:導き出された要件を採用基準に反映したり、特定のポテンシャルを持つ層へ個別研修を実施したりと、具体的な施策へ落とし込みます。
4. 具体的な分析手法と特徴
目的に応じて分析やデータ可視化の手法を選択することが重要です。代表的な手法を以下にまとめます。
| 分析手法 | 概要 | メリット・デメリット | 具体的な活用シーン |
|---|---|---|---|
| z検定 / t検定 | 集団の特徴を捉えるための手法である 。全体平均など対象集団と比較して、特定の集団に有意な差がある項目を抽出する 。 | 特定の集団(例:高業績群)が全体や対象集団と比較してどのような特徴を持つかを客観的に把握できる 。 | 性格・意欲・一般知能を測定し、管理職やリーダーに求められる能力や上昇志向を評価。 |
| 相関分析 | 項目間の関連性を探り、アセスメント項目と業績指標などの関連の強さを数値化する 。 | 「項目が高いほど評価も高い」といった関係性を端的な数値で示せる 。 | 適性検査の項目と、売上数字や業績評価の関連性の検討 。 |
| 重回帰分析 | ある変数(例:予測したい評価指標)を、複数の説明変数の値(アセスメントデータ)の一次式で予測する手法 。 | 未経験者でも将来活躍する可能性を数値で予測できるようになる 。 | 採用・選抜における将来のパフォーマンス予測や、独自の適性スコアの構築 。 |
| データマイニング(決定木) | 大量データから特定の集団(高業績群など)に共通する因子の組み合わせを、全データの組み合わせから帰納的に発見する 。 | 30名程度の比較的少人数からでも適用可能で、複数の異なる成功パターンを見つけることも可能 。関係する尺度だけでなく、その得点域まで示唆できる。 | 複雑な活躍パターンの発見や、少人数での活躍要因の探索 。 |
| クラスター分析 | 似た特徴を持つ人同士をグループ化し、人材をタイプ別に分類する手法。 | 組織内の人材タイプを可視化し、タイプごとの育成計画やチームビルディングなどのマッチングに適している 。 | 管理職を「対人重視型」「戦略重視型」などに分類し、個別の育成研修を企画する 。 |
| ヒストグラム(度数分布表) | 特定の因子の得点分布をグラフ化して可視化する手法 。 | サンプル数が少なく高度な統計分析が難しい場合でも、分布の偏りなどを視覚的に捉えることができる 。 | 採用・選抜時における、得点のばらつきや合格基準値の目安の確認 。 |
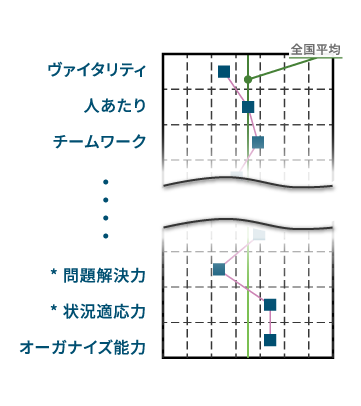
z検定 / t検定
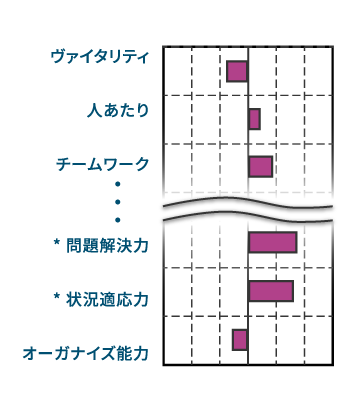
相関分析
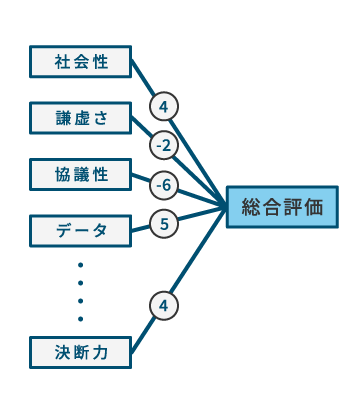
重回帰分析
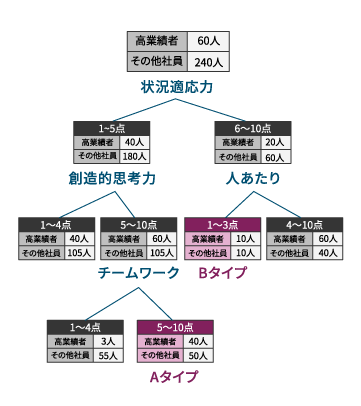
データマイニング(決定木)
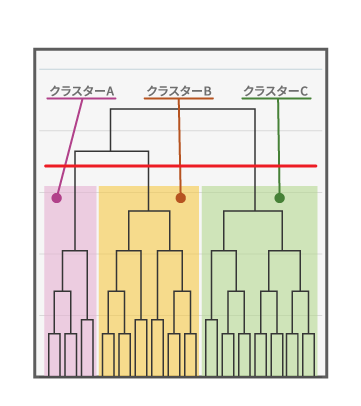
クラスター分析
.png)
ヒストグラム(度数分布表)
5. アセスメントを用いた人材データ分析でよくある質問
-
-
Q:分析にはどれくらいのデータ数(サンプル数)が必要ですか?
A:統計的には300名以上が望ましいですが、人事データ分析の実務においては 100名程度あれば対象集団の特徴を十分把握できると考えられます。最小でも 30名以上は必要です。サンプル数が少ない場合は、高度な統計分析を行う前に、度数分布表(ヒストグラム)を作成して視覚的に分布を確認することが有効です。
-
Q:高業績者(ハイパフォーマー)のデータだけで人材要件定義はできますか?
A: いいえ、不十分です。高業績者のデータだけでは、その特徴が「高業績ゆえのもの」なのか「社員全員に共通するもの」なのか判別できません。 中評価者や低評価者のデータも併せて準備し、比較して差が見られた部分こそが、高業績者独自の特徴(人材要件)といえます。
-
Q:分析に用いる「パフォーマンスデータ(評価指標)」にはどのようなものがありますか?
A: 営業職などの数値化しやすい職種では、売上数字、新規顧客獲得数、顧客維持率などが用いられます。数字で見えにくい職種では、業績評価、行動評価、表彰数、試験の合否、昇進履歴、あるいはマネジャーであればチーム業績などが指標となります。妥当性を高めるため、単年ではなく 複数年の成果を用いることが推奨されます。
1.分析の準備・データに関する質問
-
-
-
Q:採用時のデータと現在の社員のデータ、どちらを使うべきですか?
A: 目的に応じて使い分けます。 採用時のデータは「入社時点で持っていてほしい能力(成長の種)」を明らかにするのに適しており、 現在のデータは「現時点で職務に影響を与えている能力(能力開発ポイント)」の特定に適しています。
-
Q:将来の事業変化を加味した要件定義を行うことは可能ですか?
A: 可能です。統計分析は過去の実績データに基づきますが、これに経営層などへの「ビジョナリー・インタビュー」を組み合わせることで、将来を見据えた「あるべき人材像」を統合的に定義できます。
「インタビュー」を用いた要件定義の手法は こちら -
Q:自社独自の「職務適性スコア」のような指標は作れますか?
A: はい、作成可能です。 重回帰分析という手法を用いることで、複数のアセスメント項目を組み合わせ、特定の職務での評価を予測する「オリジナルの方程式(予測式)」を構築できます。
-
Q:分析はどの程度の頻度で実施すべきですか?
A: 一般的には 3〜5年に一度の実施を推奨しています。ただし、組織の人事戦略の方針転換があった場合には、その都度再定義を行う必要があります。
2. 分析の運用・実践に関する質問
-
-
-
Q:自社で分析を行うにはどうすればよいですか?
A: Excelの分析機能や統計ソフト「R」のほか、日本エス・エイチ・エルのユーザーであれば、無料で提供されている「ユーザーズページ」内の分析ツールにデータをインポートするだけで、各種統計分析が実施可能です。また、手法を学ぶための オンデマンドセミナーも提供されています。
-
Q:専門会社(SHLなど)に分析を依頼するメリットは何ですか?
A: 主に2点あります。第一に、 数値の羅列ではなく、専門コンサルタントによる深い「結果解釈」が得られることです。昨今は生成AIの発展により、専門知識がなくても統計処理やグラフ作成が容易になりました。しかし、算出された数値が自社の組織文脈においてどのような意味を持つのか、人事施策としてどう具体化すべきかという「正しく意義ある解釈」には、依然として経験豊富な専門家の知見が不可欠です。
第二に、 SHLが持つ特定の業界や職種などのベンチマークデータと比較した、独自の知見が得られることです。自社内だけのデータでは見えにくい「市場水準と比較した自社の強みや課題」を客観的に把握できるのは、膨大な外部データを持つ専門会社ならではの強みです。 -
Q:分析結果で「相関係数」が低く出た場合、どう解釈すべきですか?
A: 適性検査などの社会科学分野では、自然科学(物理など)ほど高い相関(0.7以上など)は出にくいのが一般的です。心理学的な目安として、絶対値が0.2〜0.4程度あれば「やや相関がある」と判断し、人事業務において十分に価値のある示唆として活用できます。
-
Q:選考時の評価とアセスメント結果が矛盾している場合はどうすればよいですか?
A: その場合は、評価の方法や課題を見直す必要があります。例えば、面接官が本来見るべき能力(リーダーシップ等)を評価できず「熱意」ばかり見ているといったケースが分析で判明した場合、面接官トレーニングの実施や、評価項目の精査を行うことで選考精度を改善できます。
3. 手法・環境に関する質問
-
まとめ:データ分析を「意思決定」につなげるために
人材データ分析は、それ自体が目的ではありません。真のゴールは、得られた示唆をもとに「誰を採用/選抜し、誰をどのポジションに配置し、誰をどう育てるか」というアクションを、自信を持って決定することにあります。
特に、日本エス・エイチ・エルが提供するような、科学的根拠(エビデンス)に基づいたアセスメントを活用することで、過去の実績や主観的な評価だけでは見えにくい「未来の可能性」を定量化できるようになります。人材要件は一度決めて終わりではなく、組織戦略の変化に合わせて3〜5年周期で更新していくことが、強い組織を維持するためのポイントです。データが示す深い洞察を人事の現場に還元し、一人ひとりのポテンシャルを最大限に活かす「データドリブンな人事施策」を今こそ始めましょう。

このコラムの担当者
水上 加奈子
日本エス・エイチ・エル株式会社 マーケティング課 課長
10年以上にわたりHRコンサルタントとして顧客と向き合う現場の最前線に立ち、大手企業の採用要件定義やデータ分析、育成研修等に従事。2016年に「イノベーション人材」をテーマに産業・組織心理学会で論文を発表。 その後、2020年のマーケティング部門立ち上げより現職。チーム責任者として科学的根拠に基づく発信を統括しつつ、現場知見を活かした多岐にわたるコンテンツ制作を指揮している。国家資格キャリアコンサルタント。













