
ケース1
次年度の採用計画を作成するにあたり、採用基準の見直しを検討する企業は多いと思います。この検討に際して、活躍している社員の傾向を見出すために、在籍社員のパーソナリティと成績の関連を調べる分析がよく行われます。この結果を踏まえて現在の採用基準の妥当性を評価し、より適切な新しい採用基準を作成します。
「在籍社員のパーソナリティと成績の関連を調べる」ために最も頻繁に用いられる分析手法が「相関分析」です。相関分析がどのように行われるかについてご説明します。下の図を見てください。
ある企業で活躍している営業職の行動傾向をとらえるための分析を行いました。現職の営業職にパーソナリティ検査OPQを実施してパーソナリティの定量データを取得し、加えて営業成績を基準にハイパフォーマー(HP)、ミドルパフォーマー(MP)、ローパフォーマー(LP)の3群に分け、パフォーマンス評価点を付与しました。これらのデータを使ってパフォーマンス評価点とOPQの各因子得点との相関分析を行った結果が以下のグラフです。
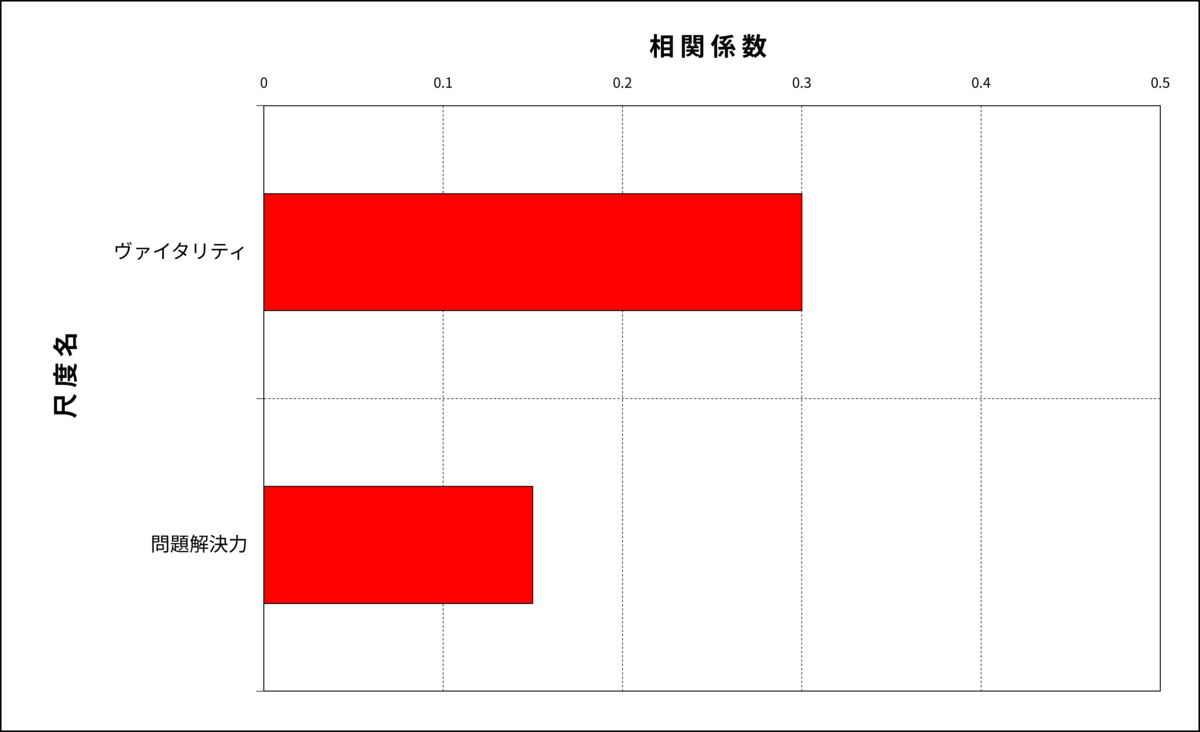
図1:相関分析結果
この図を見ると、パフォーマンス評価点とヴァイタリティ得点との相関係数は0.3であり、パフォーマンス評価点と問題解決力得点との相関係数は0.15となっています。一見するとヴァイタリティのほうが問題解決力よりも営業成績との関係が強くみられますが、同じデータを用いて分散分析を行うとより詳しい情報が得られます。下の図は分散分析の結果です。
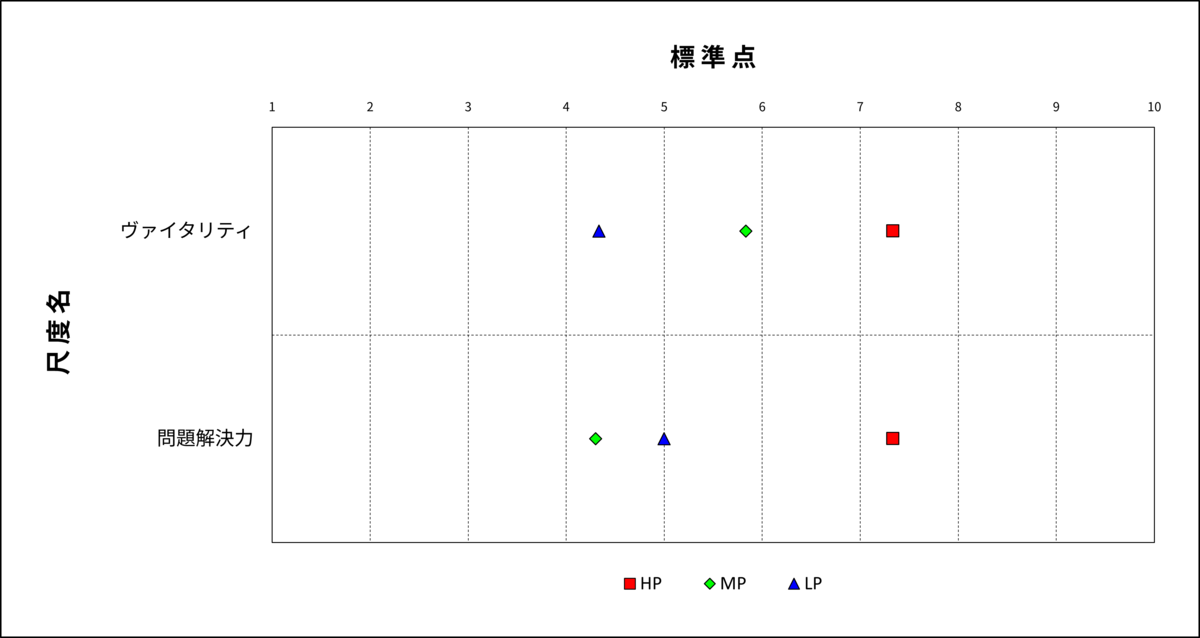
図2:分散分析
この結果を見ると、問題解決力もHPだけの特徴的な尺度として、営業成績と関係がありそうです。
相関分析は数の序列に意味があるので、点数が高ければ営業成績も高くなり、低ければ営業成績も低くなるという一本軸を見つけ出すのに適しています。
しかし、上記の問題解決力のように、ターゲットとなる一群(今回の場合はHP)にだけ特徴的でその他の群間(MPとLP)は差がない場合、あるいは序列通りになっていない場合(LP>MP)は、相関関係にはならないため、相関係数は比較的低くなります。
一方、分散分析は序列に関係なく集団としての特徴を見ているため、集団間の差を見出すことができます。
ケース2
また、こんなケースもあります。下の二つの図を見てください。
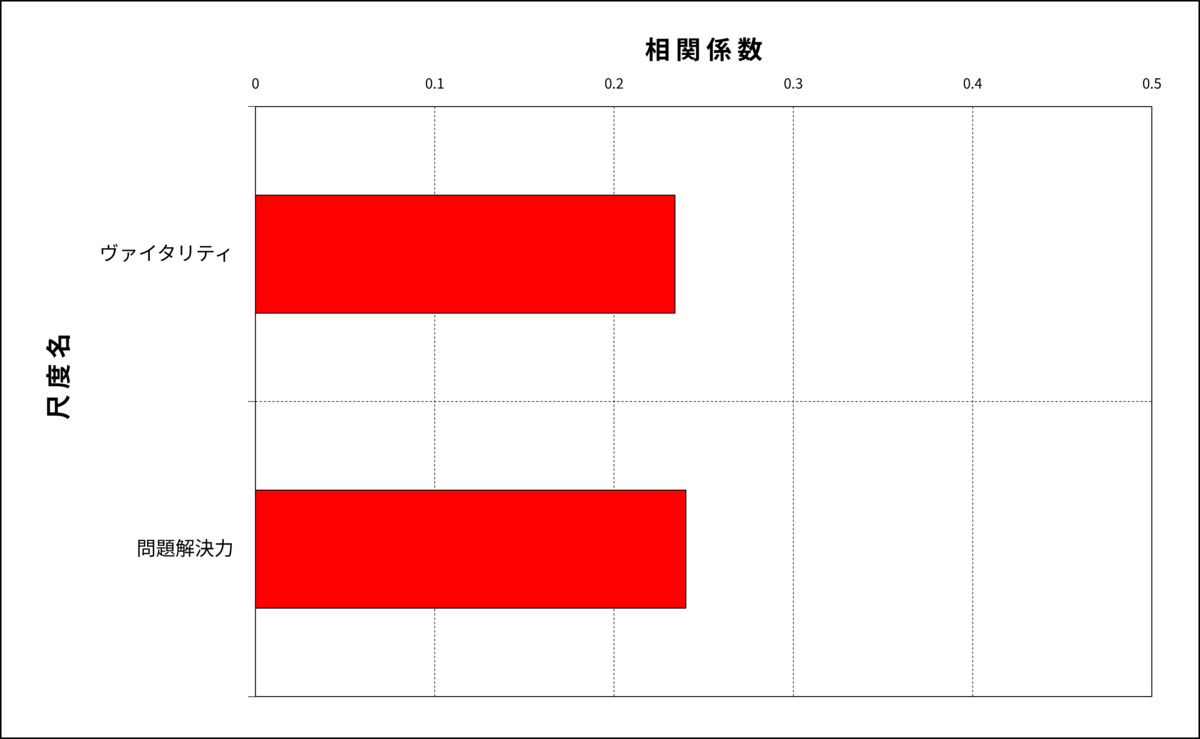
図3:相関分析
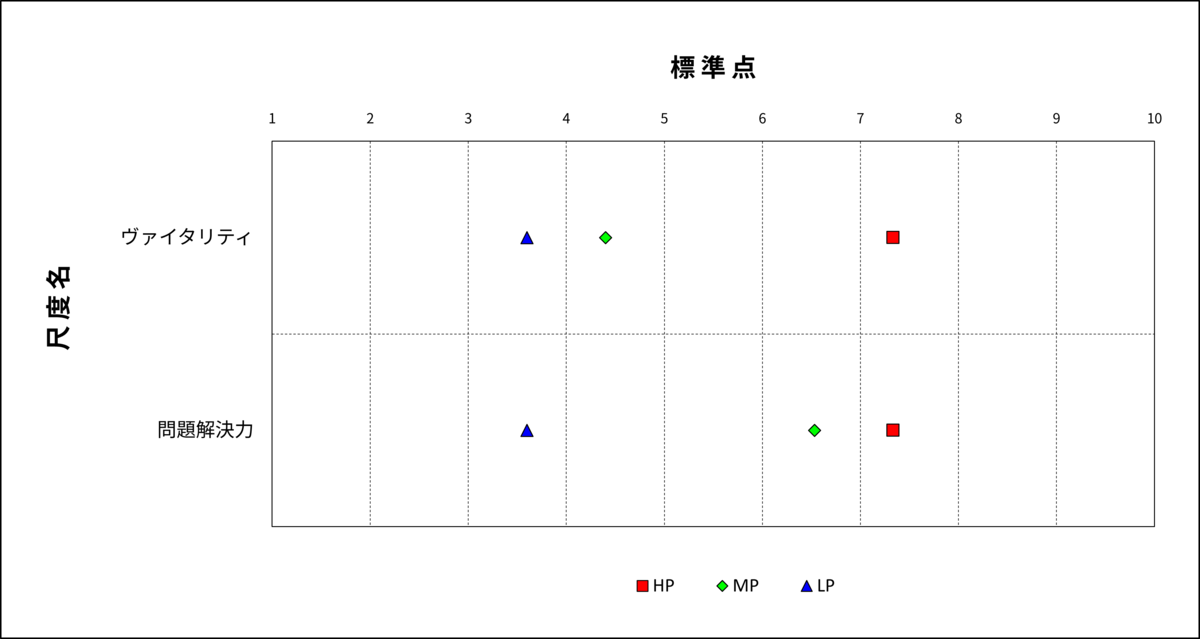
図4:分散分析
どちらも同じくらいの相関係数ですが、分散分析ではヴァイタリティ得点はHPだけが高く、問題解決力得点はLPだけが低くなっています。
ケース3
これらの因子得点を採用選考の初期段階で活用する場合、ヴァイタリティはHPのすくい上げに使えますが、LPの足切りには向かないことがわかります。逆に問題解決力はLPの足切りに向いていますが、HPのすくい上げには向きません。
さらにこんなケースもあります。
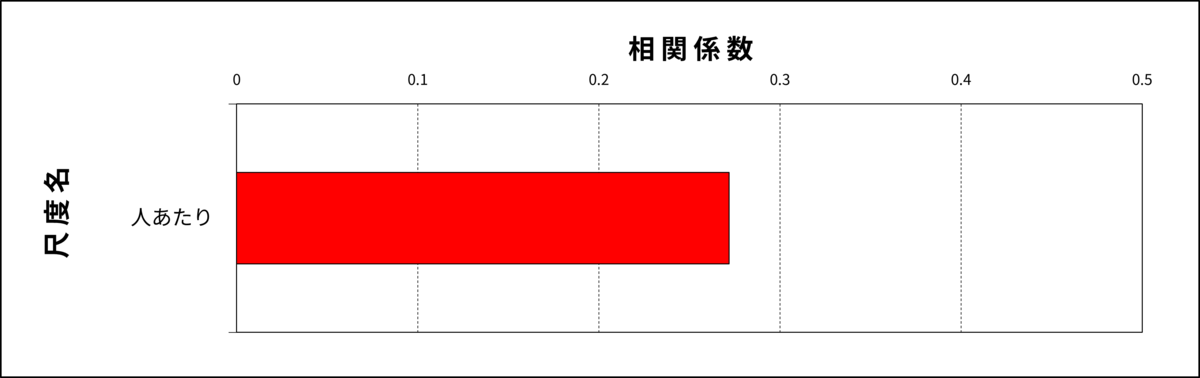
図5:相関分析

図6:分散分析
この場合、HPでも平均値が基準母集団平均(5.5点)よりも低いため、相関分析の結果だけを見て、人あたりの高得点者をすくい上げると現職のHPとは異なる特徴を持つ集団となってしまう可能性があります。
おわりに
このように、相関分析だけではテスト結果を正しく解釈し、運用するための情報として不十分なケースがあるのです。
分散分析、ヒストグラムなどの複数の分析手法やデータ集計方法を組み合わせることで、より適切な解釈を行うことが可能となります。相関分析だけでは活用ができないということではありません。分析を行う目的次第です。当社で請け負う分析の場合、成績とパーソナリティの関係を分析し、その結果をテストによる選抜に利用すること多いため、相関分析だけではなく他の手法も組み合わせることを推奨しています。
※図は全てイメージです。実際のデータから作成したものではありません。



このような方にオススメ
採用応募者や社員の適性検査データを分析したい
人事担当者が知っておくべき統計分析の基礎を学びたい
手間やコストをかけずに、自分で簡単な統計分析ができるようになりたい
セミナーのご紹介(動画)
3つの特徴
初めて統計分析に取り組む方にも分かりやすい講義
本セミナーでは、代表的な分析手法である「ヒストグラム」「t検定」「相関分析」「分散分析」を取り上げ、人事での活用場面、Excelを使った分析手順、分析結果の解釈方法などを学びます。統計や数学が苦手な方でも理解しやすいように、難解な数式や専門用語は使わず、人事場面での例を挙げながら解説していきます。
人事業務に即した演習問題
講義で分析手順や解釈方法を学んだ後、Excelを使って演習問題に取り組んでいただきます。「採用面接官の評価は適切だったか?」「活躍している社員の特徴は何か?」など、人事担当者が直面する課題がテーマになっており、サンプルデータと分析手順書を使いながら作業を進めることで実践的な分析力が身につきます。
すきま時間で学習可能
動画は1単元あたり最大7分なので、すきま時間を有効活用できます。パソコン、タブレット、スマートフォンでの視聴に対応しており、受講期間中はいつでも、何度でも視聴が可能です。

プログラム
(受講時間の目安:80分)
1.はじめに
・研修のねらいと動画の概要
2.統計分析の活用場面
・統計とは何か
・なぜ統計分析を行うのか
・分析に用いるデータ
・人事における活用場面
3.統計分析の手順
サンプル視聴
・統計分析の手順と注意点
4.統計分析の種類
・4つの分析手法:ヒストグラム、t検定、相関分析、分散分析
・ヒストグラムとは
・Excelを使った分析演習【ヒストグラム】
5. t検定①
サンプル視聴
・t検定とは
・①仮説を立てる 帰無仮説と対立仮説
6. t検定②
・②確率を求める P値
・③仮説が正しいか判断する 有意水準
・Excelを使った分析演習【t検定】
7.相関分析
サンプル視聴
・相関分析とは
・相関係数とデータ分布
・相関分析の注意点
・Excelを使った分析演習【相関分析】
8.分散分析
・分散分析とは
・多重比較
・Excelを使った分析演習【分散分析】
9. (参考)無料分析ツールの紹介
・日本エス・エイチ・エル株式会社の「無料分析ツール」とは
10.おわりに
・統計分析を行う際のポイント
- ※本セミナーの演習ではExcelを使用します。なお、本セミナーで紹介するExcel各部の名称が、お手元のExcelのバージョンによって若干異なる場合があります。
- ※Excelは、米国Microsoft Corporationの米国およびその他の国における登録商標または商標です。
- ※本セミナーは当社が主催する独立したサービスであり、Microsoft Corporationと関連のある、もしくはスポンサーを受けるものではありません。
セミナー概要
主催
日本エス・エイチ・エル株式会社
対象者
企業の人事・採用・育成業務に従事されている方(同業者、学校法人、個人の方はお申込できません)
受講費
受講者1名様につき5,000円(消費税等別)
※「受講人数無制限」の年間契約プランもございます。詳しくは、担当コンサルタントまでお問い合わせください。
受講期間
受講用URLメールの到着日から3週間
お申し込み方法
フォームよりお申込みください。お申し込み受付後、原則2営業日以内に受講用URLとログインID、及びログインパスワードの設定方法を記載したメールをお送りします。
※届かない場合は、事務局までお問い合わせください。
お支払い方法
受講用URL等を記載したメール送信後、当社他サービスの利用料金と併せて請求させていただきます。
※振込手数料は貴社ご負担にてお願いいたします。
動作環境
OSとブラウザ
Windows
OS
Windows 10、11
ブラウザ
Microsoft Edge(最新版)、 FireFox(最新版)、Google Chrome(最新版)
Mac
OS
MacOS High Sierra 10.13 以降
ブラウザ
Safari(最新版)
iPhone/iPad
OS
iOS 14.0 以降 / iPadOS 14.0 以降
ブラウザ
Safari(最新版)
Android
OS
Android 8.0 以降
ブラウザ
Google Chrome(最新版)
注意事項
- ・ブラウザのJavaScript、Cookie、SSLの設定が有効である必要があります。
- ・セキュリティソフトウェアまたは、アンチウイルスソフトウェアのセキュリティ機能によっては正しく視聴出来ない場合があります。
- ・株式会社プロシーズが提供するeラーニングシステム「LearningWare」を使用します。
注意事項
・1つのログインIDで、同時に複数の端末で視聴することはできません。
・ログインIDやパスワードの共有、第三者への譲渡を禁止します。また、セミナーの録画・録音、転載、第三者への公開等は固くお断りいたします。
・利用可能期間中にコンテンツの受講が完結しなかった場合や、サービスの利用が無かった場合にも、利用期間の延長や返金は行いません。
お問い合わせ
日本エス・エイチ・エル株式会社 セミナー事務局
Eメール training@shl.co.jp

関連する導入事例





















人材データ分析とは?
人材に関連するデータを集め分析することで、効果的にタレントマネジメントを行うための知識が得られます。分析によって高業績者のコンピテンシー、選考の評価基準、部署別の特徴や従業員のポテンシャルなど、様々な組織・人材における問題や課題を可視化します。採用、配置、育成、組織開発などの人事施策を改善できます。


お客様の課題を解決する方法をご提案
課題や問題意識などの目的を明確にするため、コンサルタントがヒアリングします。ご要望に応じて、分析対象の選定、目的変数・説明変数の検討、分析手法の採択、分析作業、分析結果の活用をサポートします。
導入シーン
人材要件を定義する
特定の職種やポスト等の人材要件を定めるために、人材データ分析を行います。当該職種・ポストにおける人事評価等のパフォーマンスデータを用い、パフォーマンスを予測する一連の変数(知的能力・パーソナリティ特性など)を特定します。オリジナルの尺度を作成することも可能です。

従業員を可視化する
社員の属性などの人材情報を可視化して、経営・事業戦略と人材・組織とのギャップを明らかにし、組織・人材に関する問題の発見、人事施策の導入や見直し、人事的な意思決定の改善などに役立てます。タレントマネジメントの基礎となる取り組みです。

選考を振り返る
採用選考や昇進試験等において、評価や判断に妥当性があったかを確認する振り返りの分析です。 選考における合格者と不合格者、高評価者と低評価者を分ける要因を検出し、当初の想定と一致しているかを検証します。人材要件定義分析の結果と照合すると、より効果的です。

関連する導入事例



















感覚的な判断が支配する人事の世界に、科学的な目線を導入する第一歩。
「面接員の主観・評価傾向」をデータで可視化する三井物産の取り組みを紹介します。
※本取材は2020年7月に行いました。インタビュー内容は取材時のものです。
三井物産株式会社
金属資源、エネルギー、ヘルスケアなどの分野における多種多様な商品販売と各種事業の展開
卸売業
5,676名 (連結従業員数45,624名)(2020年3月31日現在)
インタビューを受けていただいた方
清水 英明 様
三井物産株式会社
人事総務部人事企画室 マネージャー
インタビューの要約
主観的な面接評価に対する課題意識があり、面接員の「評価の目線」を科学的・定量的に可視化することに挑戦した。
学生と面接員へのアセスメント(パーソナリティ検査OPQ)を行い、面接員の評価傾向を分析した結果、面接員ごとに固有の評価傾向(評価のクセ)が浮き彫りになった。
適切な評価を行えるように面接員トレーニングを拡充し、面接手法の改善に成功。
今後の目標は、「人事にデータを使う」ということを、人事総務部の施策に浸透していくこと。数字や明確な根拠に基づく、科学的なタレントマネジメントを推進していきたい。
「なぜ合格?なぜ不合格?」科学的じゃない採用の世界に危機感。
私は大学で農学を勉強しており、大学卒業後、青年海外協力隊としてアフリカで果樹栽培指導員として活動し、その後、大学院でアフリカの農家に関する調査研究をしました。三井物産に入社し、食料部門のチョコレート原料などのトレーディング、シンガポール駐在時の戦略企画業務、再び食料部門の乳製品のトレーディング・事業投資などに従事していました。学生向けのインターンシップに現場社員の立場として協力したことが契機となり、当時の採用担当の室長から「人事総務部に来て採用を担当しないか」というお声がけをもらい・・、といった流れで人事に異動してきたという経緯です。
人事に来て初めての採用面接を終えた夏。採用って“科学じゃない”なぁと思いました。この学生はなぜ合格?なぜ不合格?これって科学的に説明できるのだろうか、何に基づいて判断しているのだろうかと。人事の世界は感覚的に判断している部分が多く、面接員の主観に基づいて意思決定されるところに危機感を持ちました。ちょうどその時、前任者が進めていた日本エス・エイチ・エルのパーソナリティ検査OPQによる人材可視化プロジェクトを引き継いだので、彼の蓄積してきた知見をどうにか使えないだろうかという気持ちもありました。
まずは面接員へのトレーニングが必要と考え、研修内容を作りこんでやってみたはいいものの、結果としては従来の傾向に変化はありませんでした。2年目の採用面接でも、私のモヤモヤは残りました。

面接員の「主観」は数字にできる!採用から科学的人事への第一歩。
このままじゃいけないと思っていた矢先、日本エス・エイチ・エルからある分析事例についてのダイレクトメールを受け取りました。その分析というのは、面接員の評価傾向をOPQで定量化・可視化するというもの。「これ、使える!」とスイッチが入りました。どのように面接員の評価傾向を可視化するのかを尋ね、自分で分析してみたところ、面接員の主観や評価傾向が明らかになり、これはすごいことになりそうだと思いました。まずはインターンシップに参加する学生を選ぶ面接で試してみました。面接参加者のOPQの各因子得点と面接評価点を分析してみると、予想通り面接員毎の「主観」の傾向が出たので本格的に動き出しました。
この取り組みに日本エス・エイチ・エルのアセスメントを用いたのには、いくつかの理由があります。日本エス・エイチ・エルの主催する勉強会に頻繁に参加していたこと、グローバル展開していること、継続的に面接員トレーニングを依頼していたこと。また、重要なのは相手の価値につながるかどうか、こちらが何を売りたいかではなく、相手が何を求めているかが第一、という私自身が営業時代に大事にしていた価値観を言葉にせずともわかってくれる。それが日本エス・エイチ・エルに色々と相談している理由です。
三井物産に必要な人材を採用する、集中的な面接員トレーニングに成功。
面接員の分析によって得られた結果は2つあります。一つは、面接員個々の評価の可視化。それぞれの面接員がどのような学生を合格にする傾向があったか。言わば個々の主観の数値化です。もうひとつは、三井物産の面接全体の評価傾向の可視化。全面接員の評価を通じて、どのような学生を合格にする傾向にあったかです。これらは面接評価点とパーソナリティ検査OPQの各因子得点との相関関係を分析することで検証できました。
最初にこの傾向をつかんだので、インターンシップ選考の時に構造化面接を導入し、着目すべきパーソナリティ因子について深堀をする設計にしました。その結果、評価傾向の波形が、意図した通りに変化しました。つまり、面接員の評価傾向は数字にできるし、面接の設計によってある程度コントロールできる、ということです。
そこで当社の求める人材はどういう人材か、求める人材を選抜するためにどのような面接を行うべきかを再検討し、面接員トレーニングを作り直しました。まずは当社社員として必ず必要となる、ある一つの側面に焦点をあてて1次面接をしようと面接員に説明しました。加えて面接員に過去3年分の自分の面接評価傾向を見せ、自分の主観の傾向や見逃しがちな点について意識づけし、本選考を実施しました。その結果、願った通りの結果となりました。
もう一つの企みは、データに基づく人事施策への意識醸成。
私にはもう一つの企みがありました。「人事に数字を使う」という意識を、現場社員である面接員や人事総務部全体に醸成することです。こういった取組が、数字や明確な根拠に基づく科学的なタレントマネジメントをするべきだという意識醸成につながる第一歩にしたいと思っていました。面接員が普段仕事をする現場でもそういう考え方が浸透するのは大事なことですよね。人事施策はデータに基づいて行うものだという雰囲気を作るつもりでやっていました。
今後のタレントマネジメントの進め方についてですが、まずは各自が脳内に持っている、人に対する印象や記憶を、できるだけ客観データに変換して蓄積していきます。あるポストの候補者を探そうというとき、上司の直感だけで「あいつだ」と決めてしまうと、情報範囲が限定的になってしまう。頭の中の情報を客観的なデータとしてアウトプットして、そのデータを使いながら配置を検討すべきです。候補者として世界各国で採用された人が同じように並び、比較され、よりポストに見合った人が配置される、そういうタレントマネジメントが理想です。
頭の中の情報をアウトプットすることは今回の分析と繋がっています。主観的な面接評価傾向を客観的な数値に置き換え、より良い方向へ最適化していく、そういった取組をグローバルタレントマネジメントでも実現したいですね。

今、私は次世代の人事総務システムプロジェクトを担当しています。このプロジェクトには国内の人事給与システム再構築とグローバルタレントマネジメントという二つの柱があります。これまでは日本で採用された社員が中心だった人材情報の可視化を海外で採用された人材にも拡げ、その人材データをもって適材適所を検討できるようにプロジェクトを進めています。ちなみに、グローバルタレントマネジメントについての問題意識はシンガポール駐在時の経験によって形成されました。現地で採用された優秀な社員は三井物産でのキャリアに限界を感じていました。これでは本当の適材適所ではないですよね。また、会社が今後目指す方向であるグローバルマーケットにおいては、多様な人材のポテンシャルを最大限に活用する必要があります。今はまだこれらを推し進める仕組みが十分とは言えません。
グローバルタレントマネジメントに関する日本エス・エイチ・エルへの期待として、人材アセスメントにおいて蓄積するデータ・分析手法・結果の活用について、ぜひアドバイスが欲しいですね。
次世代の人事・総務システムプロジェクト・二つの柱
- 国内の人事給与システムの再構築
- グローバルタレントマネジメント
担当コンサルタント

日本エス・エイチ・エル株式会社 HRコンサルティング2課 課長
横山 武史
清水さんから面接員の評価傾向の可視化について話をいただいた際、私は評価傾向をとらえた後、その結果をどのように具体的な選考に活用するかが重要ですと申し上げました。すると、データそのものを選考に用いるのではなく面接員の評価を適切な方向に導く指標としてデータを活用できるのではないかとおっしゃいました。そうであればと、私はOPQの分析方法と注意点をお伝えし、今まで当社が行ってきた面接員ごとの評価傾向分析や面接評価構造分析の事例を紹介しました。もちろん分析業務を当社でお受けすることもできましたが、清水さんがご自身でデータを扱うほうが仮説検証を素早く繰り返すことができると思いましたし、清水さんもそれを希望されていました。その後の分析は順調に進み、分析結果を面接員のトレーニングに活用したいというご要望をいただきました。
分析結果を面接員の評価改善につなげる清水さんのアイデアを具現化する面接員トレーニング開発に携わらせていただけたのは我々にとって有意義な経験でした。どうもありがとうございました。
現在進行中のグローバルタレントマネジメントにおいてもSHLグループの知見と情報を駆使してお力になりたいと考えております。







関連するおすすめのサービス



関連する導入事例




t検定とは
t検定とは、2つの集団(標本)の平均値の差に意味があるかを検定する方法です。t検定にはいくつか種類がありますが、本コラムでは独立した2つの集団を扱う「対応のないt検定」におけるスチューデントのt検定について説明します。例えば、採用における募集方法を変更した際に、昨年の応募者集団と比べて今年の応募者集団に期待した変化が見られているかをOPQで確認する場合や、育成方法を検討するために高業績者とその他社員の違いをOPQで明確化したい場合などで活用できます。
2つの集団(標本)の平均値を単純に比較して異なっていたら良いのではないか、と思われるかもしれません。しかし、標本である以上、その差には必ず偶然のばらつき(サンプリング誤差)が含まれています。このばらつきの影響で、実際には母集団に差がないのに、標本データだけを見ると違いがあるように見えることがあります。そのため、統計的に有意な違いがあるかどうかも含めてデータを評価することで、より的確な施策を打つことができるようになります。

z検定とt検定の違い
z検定もt検定も「平均値の差に意味があるか」を調べる方法ですが、次のような違いがあります。z検定
- 母集団のばらつき(分散や標準偏差)が既知の場合に用いる。
- 標本サイズが大きい場合に適している。
- 例: OPQ得点は大規模な受検者集団で標準化されており、母集団(一般集団)の平均(5.5)と標準偏差(2)が分かっています。このように、比較対象となる母集団の統計量が既知の場合に、標本の平均値との違いを検定する方法がz検定です。
t検定
- 母集団のばらつきが未知で、標本データから推定する必要がある場合に用いる。
- 標本サイズが小さい場合に適している。
- 例:OPQ得点の母分散は既知ですが、観測された標本のサイズが小さい場合、母分散ではなく標本分散を利用して推定した方が適切であり、t検定を使うのが望ましいです。
このように、母集団の情報がどこまで分かっているか、標本サイズが十分かどうかによって、z検定とt検定の使い分けが必要になります。次に、具体例を用いて詳しく説明していきます。
高業績者とその他社員の比較
企業Aでは開発部門500人(高業績者=100人、その他社員=400人)における業績をあげるべく、育成方法を検討したいと考えています。育成担当者は高業績者とその他社員の違いを「問題解決力」にあるのではないかと考えていますが、データから明確化するために、開発部門500人からランダムに150人(高業績者=30人、その他社員=120人)を選択してOPQを実施することにしました。統計的検定における帰無仮説と対立仮説
高業績者とその他社員とでは「問題解決力」の平均が異なると予想している場合は下記の仮説になります。- 帰無仮説:
- 「問題解決力」における高業績者の母集団平均とその他社員の母集団平均の差は0である
- 対立仮説:
- 「問題解決力」における高業績者の母集団平均はその他社員の母集団平均より高い(または低い)
その差は誤差か
OPQ結果より、高業績者30人の「問題解決力」の平均は7.677、標準偏差2.031、その他社員120人の「問題解決力」の平均は5.611、標準偏差2.062でした。高業績者の母集団平均とその他社員の母集団平均の差が0であれば、高業績者の標本30人の標本平均とその他社員の標本120人の標本平均の差も0となるはずですが、標本から得られた値は0ではなく2.066です。この2.066が母集団から標本がランダムに抽出されたことによる誤差(標準誤差)と判断するのかどうかを計算していきます。
標準誤差の算出
t検定では、2つの標本のばらつきを統合して標準誤差を計算します。これは、2つの標本の平均値の差を検定する際に、各標本のばらつきがどの程度であるかを考慮するためです。なぜなら、データがばらついている標本では平均値の差を見つけにくく、逆にデータがまとまっている標本では敏感に差を検出できるからです。また、標本サイズが大きい標本は「より正確な情報を提供する」と見なされるため、ばらつきを統合する際には、各標本の分散を標本サイズに応じて加重平均(重み付け)します。これにより、より信頼性の高い標本が差の検出において強調されます。

上記式は、各標本の分散(標準偏差を二乗したもの)を標本サイズに応じて加重平均していることを意味しており、算出された値は統合標準偏差です。
この値に√1高業績標本人数 + 1その他標本人数をかけたものが標準誤差になります。
t値の算出
t値とは、帰無仮説(高業績者の母集団平均とその他社員の母集団平均の差は0である)を基準に、標本データ(高業績者標本平均とその他社員標本平均の差)が、その仮定された差(0)から標準誤差の単位でどれだけ離れているかを算出する指標です。t値が大きいほど、標本データが帰無仮説から大きく離れていることを示し、帰無仮説が棄却される可能性が高まります。
t分布表の自由度148、5%棄却域の値(両側検定の場合2.5%で1.976)よりも大きいと帰無仮説は棄却されます。上記は4.923ですので、帰無仮説は棄却されます。(※自由度=(30-1)+(120-1)=148)
イメージとして捉える
検定統計量の計算としては上記のものになりますが、イメージとして分かりやすくするため、下記に信頼区間と合わせた図を載せます。高評価者の標本30人とその他社員の標本120人が同じ母集団(差が0)から抽出されたのであれば、下記のような信頼区間になりますが、標本平均値差は2.066で区間内に入っていません。よって、帰無仮説は棄却されます。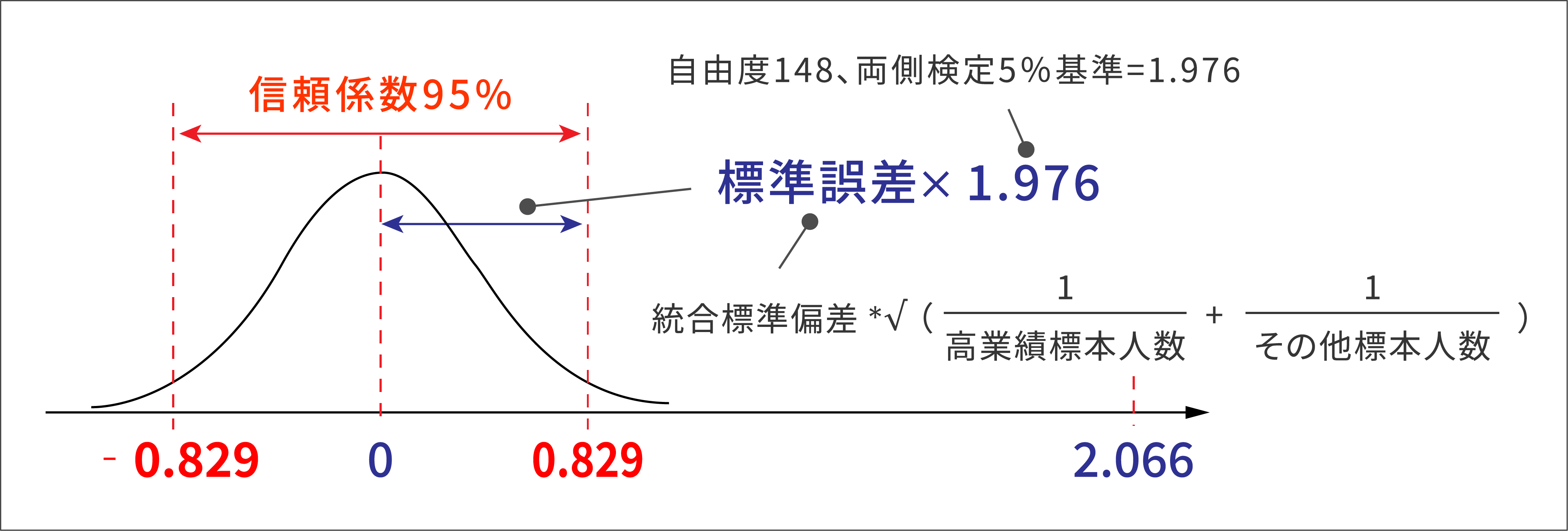
おわりに
上記例では、高業績者はその他社員と比べて「問題解決力」が統計的に有意に高い(=誤差による差ではない)ことが明らかとなりました。よって、「問題解決力」に関連した育成を行っていこうという判断ができるようになります。実際には、統計的に有意でも、実務的に意味のある差かどうかといった点や、定性的な情報も含めて育成方法については検討していくことになると思いますが、「統計的に有意であるかどうか」は課題に対する解決策の判断に有効な手段の1つだと思います。 データ分析の解釈や分析結果の報告書などに用いられる「統計的有意」という言葉。データ分析が身近になる中で、「統計的有意」がどのような考え方に基づくものか、またどのように算出されるのか疑問を抱く方もいるかと思います。今回はこの「統計的有意」について、関連する用語とともにz検定を用いて解説します。
母集団と標本
はじめに、データを収集するための調査は全数調査と標本調査に分けることができます。知りたいことの対象者全体を母集団といい、母集団全体について調査することを全数調査、その一部を調査することを標本調査といいます。例えば、自社の営業社員(500人)がどういったパーソナリティなのかを知りたいけれど、期間やコスト面から一部の営業社員(100人)にのみパーソナリティ検査OPQを実施する場合は、標本調査となります。全営業社員が母集団、データ収集を行った一部の営業社員が標本といえます。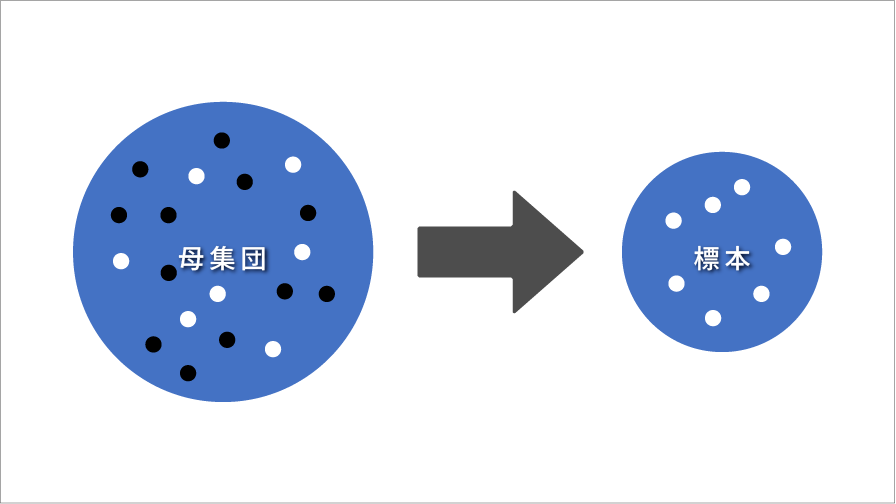
統計的推定
次に、統計的推定が何かを知っておきましょう。統計的推定とは、母集団のある値(平均値や標準偏差など)を、標本を用いて推定することを指します。標本である100人の営業社員のOPQデータを集計し、「ヴァイタリティ」尺度の平均値が7.016であったとすると、全営業社員の平均(母集団平均)が、標本から7.016と推定されたということになるのです。統計的検定
統計的検定とは母集団に関する予想(「集団Aの平均<集団Bの平均」など)が、正しいといえるかどうかを標本から判断することを指します。例えば、全営業社員(母集団)の「ヴァイタリティ」平均は、比較対象集団の平均より高いという予想を100人の標本から正しいといえるかどうかを判断します。点推定と区間推定
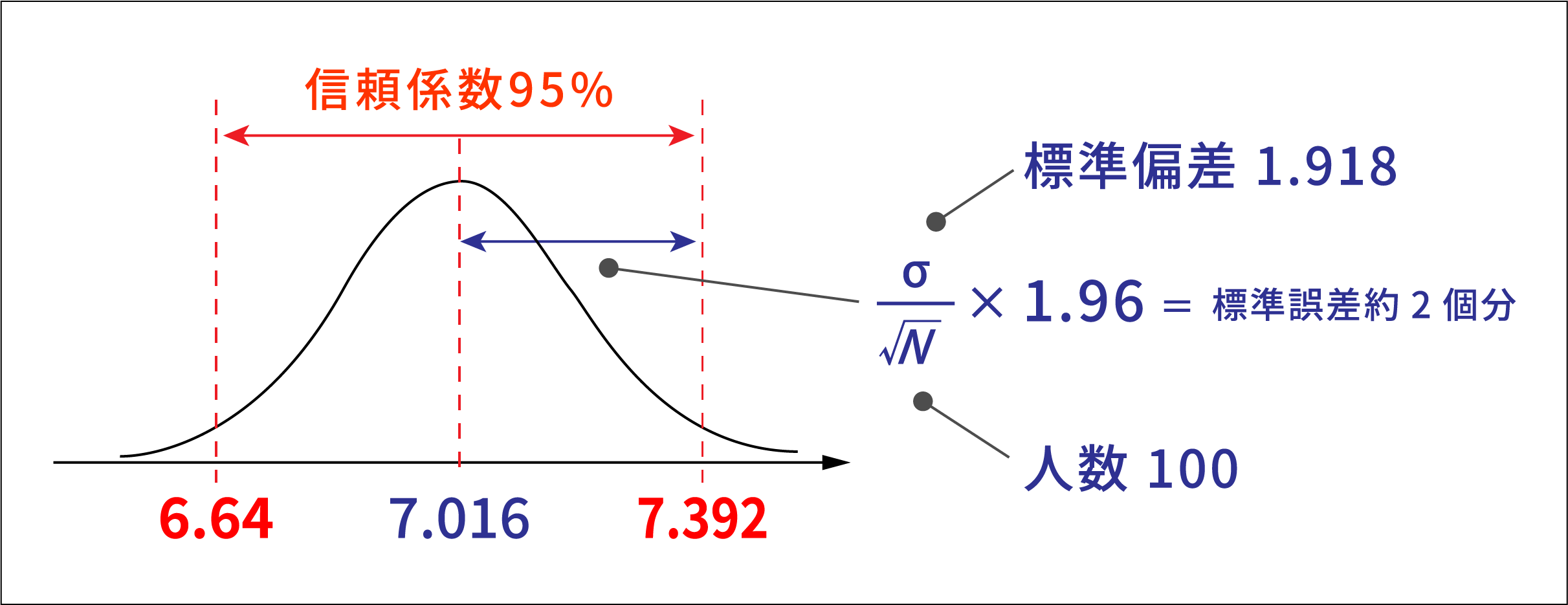
点推定とは、一つの値で母集団の平均などを推定することを指します。上記では全営業社員の「ヴァイタリティ」の平均値は、7.016であると100人の標本から推定していました。点推定は、標本の人数を多くすれば、推定の精度は上がりますが、母集団のものと完全に一致するという可能性は低いです。そこで、その推定がどの程度正しいかを示す指標として標準誤差があります。標準偏差と標準誤差は異なるものです。標準偏差は標本分布のばらつきを示しますが、標準誤差は標本から得られる標本平均(ここでは100人の「ヴァイタリティ」の平均値7.016)のばらつきの大きさを示します。区間推定とは、一つの値ではなく、区間で母集団の平均などを推定することを指します。推定する区間を信頼区間といい、母集団の平均などが信頼区間に含まれる確率を信頼係数といいます。「95%信頼区間」が一般的に用いられることが多いですが、「母集団から100回標本をとりだし、それぞれ母集団の平均の95%信頼区間を求めた場合、95回程度はその区間内に母集団の平均が入る」ことを指します。100人の標本平均が7.016、標準偏差が1.918だった場合、全営業社員の平均(母集団平均)の95%信頼区間は6.64~ 7.392となります。
統計的検定における帰無仮説と対立仮説
帰無仮説は予想が正しいことを主張するために否定したい前提(対立仮説を否定する内容)です。対立仮説は予想している内容、主張したい内容です。例えば、全営業社員の「ヴァイタリティ」平均値が比較対象集団よりも高いと予想している場合は下記の仮説となります。- 帰無仮説:
- 全営業社員の「ヴァイタリティ」平均値は比較対象集団と同じである
- 対立仮説:
- 全営業社員の「ヴァイタリティ」平均値は比較対象集団と同じでない(差がある)
100人の標本平均が帰無仮説のもとでは5%以下の確率でしか生じない大きな値(あるいは小さな値)の場合、帰無仮説は棄却され、対立仮説が採択されます。これが「統計的に有意に差がある」の考え方になります。
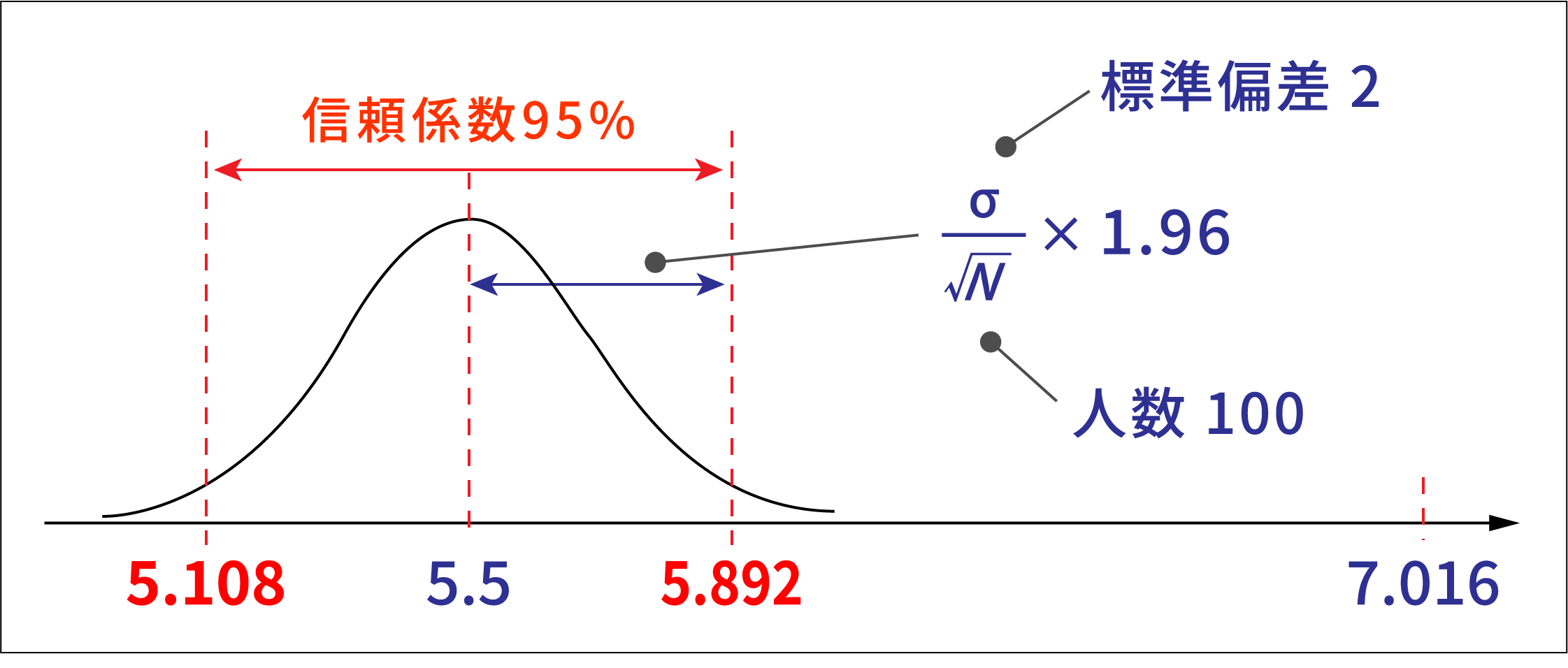
z検定
最後に、z検定を用いて理解していきましょう。OPQ得点は大規模な受検者集団で標準化された得点であり、既に母集団(=一般集団)の平均と標準偏差が分かっている分布となります(平均5.5 標準偏差2)。当社ではこの一般集団を比較対象集団として、その平均と標本の平均との差に統計的に意味があるかどうかを検定する方法をz検定としています。全営業社員の標本100人がその母集団(=一般集団)からランダム抽出された集団であれば、下記のような信頼区間となるはずですが、標本平均は7.016ですので、5%よりもずっと低い確率でしか得られない大きな平均値(誤差で生じたとは考えにくい平均値)であると考えられます。よって、全営業社員の「ヴァイタリティ」平均値は5.5である(比較対象集団と同じである)という帰無仮説は棄却され、全営業社員の「ヴァイタリティ」平均値は.比較対象集団と同じでないという対立仮説が採択されることになります。つまり『全営業社員の「ヴァイタリティ」平均値は一般集団よりも統計的に有意に高く、特徴的である』といえるのです。
イメージを捉えるために信頼区間から考えると上記のようになりますが、実際の検定統計量の計算としては下記になります。

このz値が正規分布表の5%棄却域の値(両側検定の場合2.5%で1.96)よりも大きいかどうかによって帰無仮説を棄却するかを判断します。
以上が「統計的有意」の考え方であり、計算の仕方となります。
おわりに
いざ調査、分析、解釈では、「人数が多いと統計的有意になりやすいとは?」「5%有意とは?」等、さまざまな疑問がわいてくると思いますが、疑問解消の参考となれば幸いです。統計分析の最大の特徴は、平均値だけでは分からない「有意差(偶然なのか、意味がある結果なのか)」を検証できる点です。しかし、結果が有意かという1点のみを重視してしまうと、その背景にある情報を見逃す可能性があります。
今回は人材データの分析結果を解釈する際に注意すべき点についてご紹介します。
有意水準とは
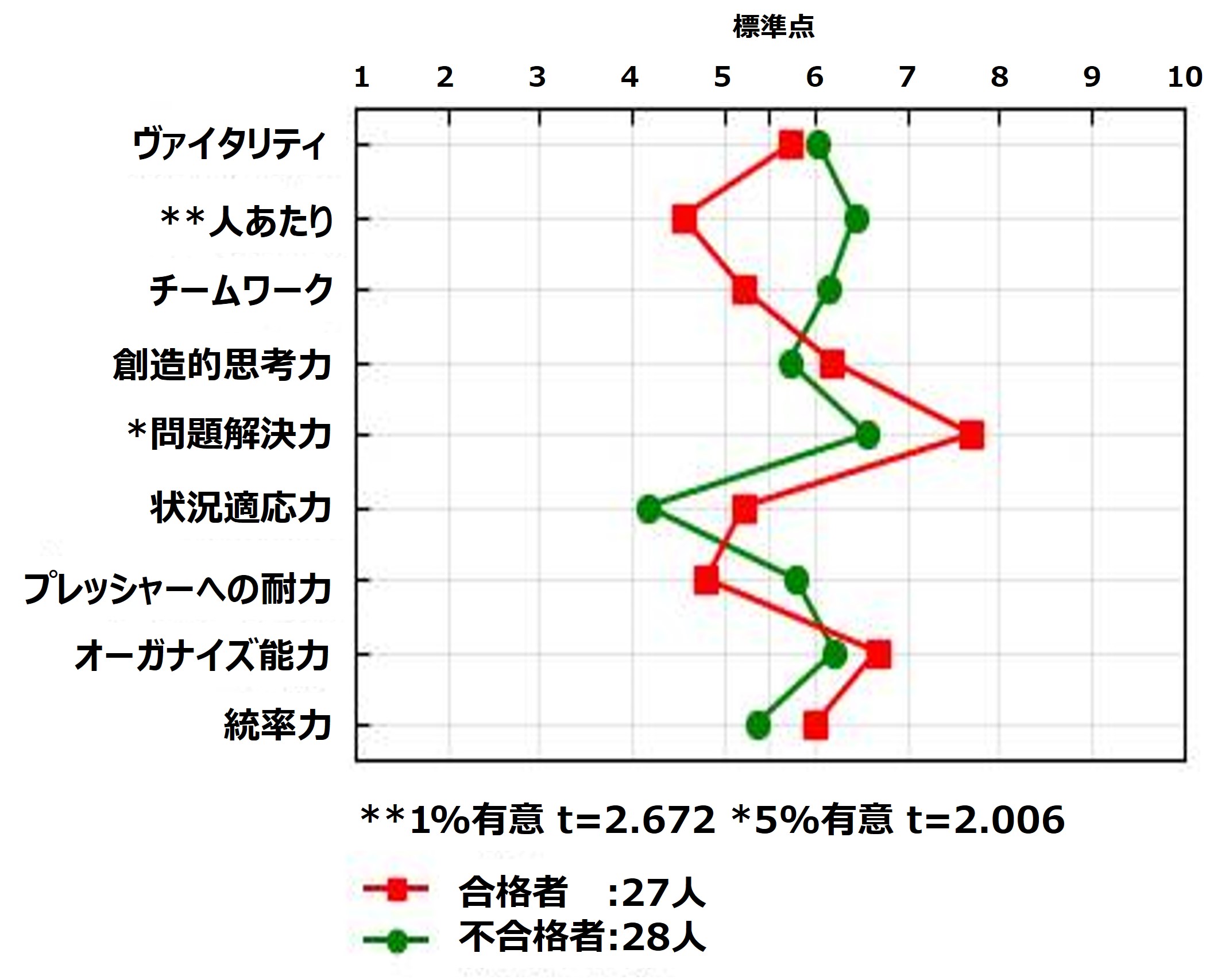
上図はt検定結果をグラフ化したものです。各群の平均値を点で表示し、2群間に有意な差があった場合には、該当する尺度名の横に*(アスタリスク)を1または2個表示させています。
*は有意水準を識別するための記号です。有意水準とは、分析結果が偶然生じたのではなく、意味があるといえる確率のことです。*が1個の場合は「95%以上の確率で偶然ではない、確実な差があること」と解釈します。また*が2個の場合は「99%以上の確率で偶然ではないこと」と解釈します。
このグラフにおいて、2群間の差の大きさは点の開き具合で確認でき、その差がどのくらいの確率で発生するのかは*の数で確認できます。仮に大きな差が開いていても、有意水準に達していない場合は意味がないと解釈します。分析結果を読み解く際には、*がついている尺度を重点的に確認します。
落とし穴1:分析結果は対象人数に左右される
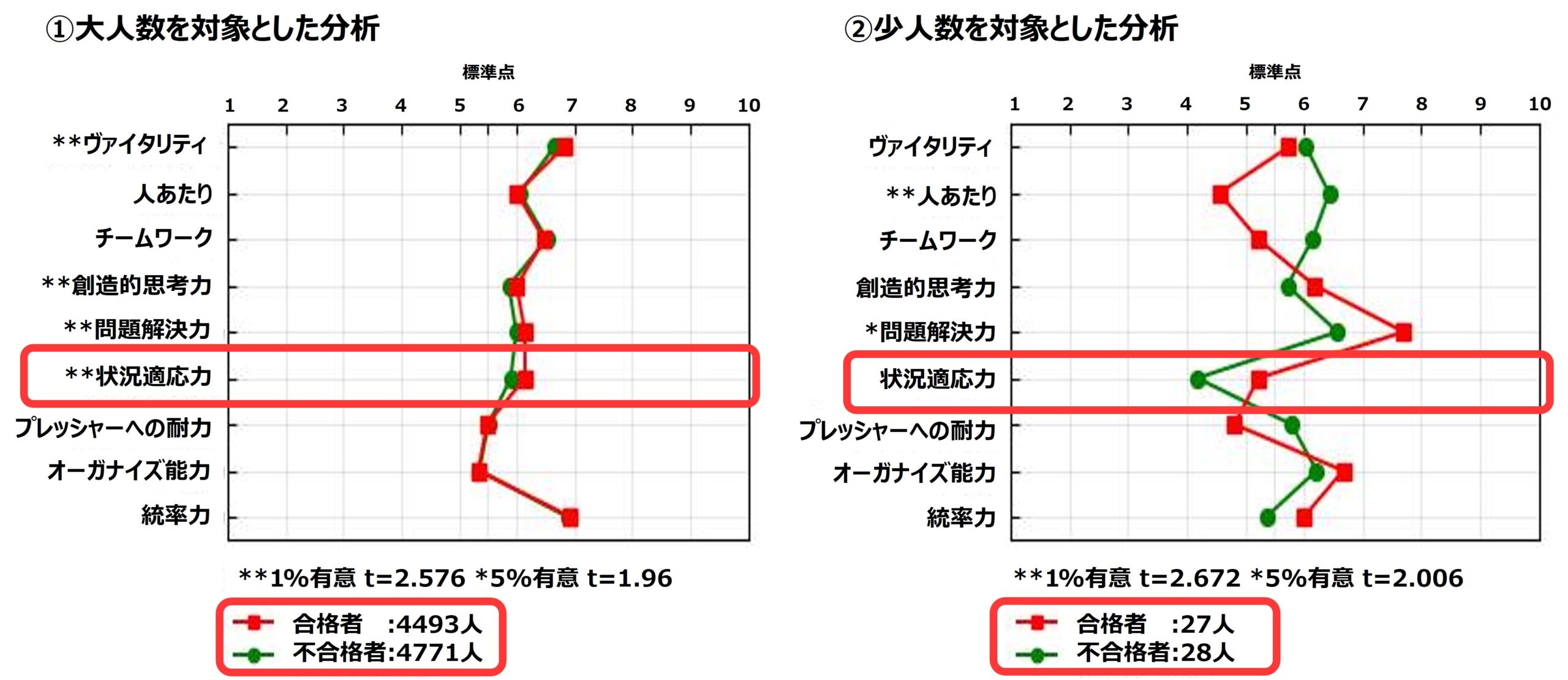
上にある2つのグラフは、どちらも合格者/不合格者間の適性検査得点を比較したものです。しかし各群の人数が大きく異なっています。
「状況適応力」に注目してください。①大人数のグラフでは、2群間の平均値に大きな差が見られませんでした。しかし、*が2個もついています。一方、②少人数のグラフは平均値の差が①よりも大きいですが、*は1個もついていません。結果、「状況適応力」において、②少人数のグラフは有意差がなく、①大人数のグラフは差こそ小さいものの、99%以上の確率で偶然ではない差が存在していると解釈します。
①のように、対象人数が多い分析を実施した場合、平均値の差が微々たる場合でも結果に*がつくことがあります。このような場合は、*がついていることに加え、平均値差が一定以上開いている尺度、またはその中での得点差が大きい尺度に絞って注目していくことをお勧めします。例えば、各群の人数が1000人以上の場合、平均値の差が1以上開いている尺度に絞って解釈を進めていく、などです。
落とし穴2:選抜された人が対象となる分析では結果が表れにくい
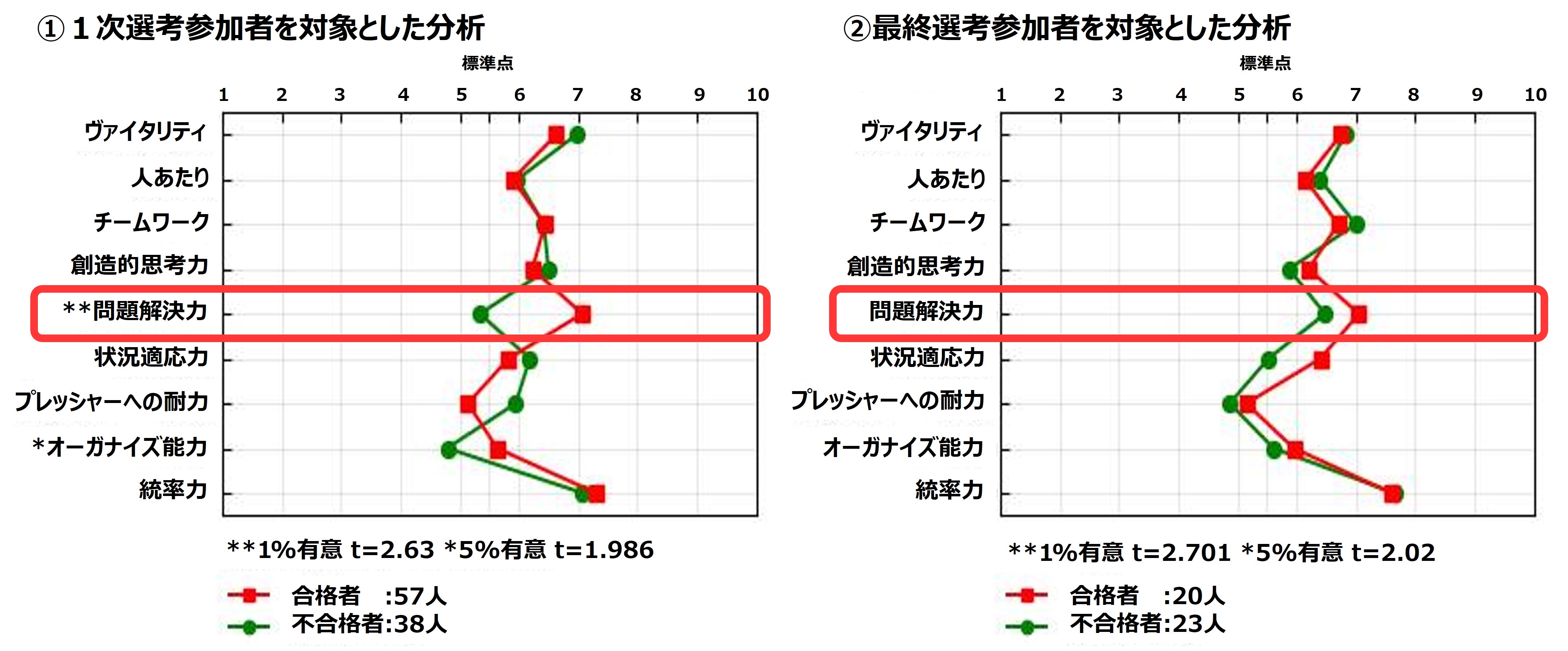
上にある2つのグラフは、各選考段階における合格者/不合格者間の適性検査得点を比較したものです。
「問題解決力」に注目してください。①1次選考のグラフでは、*が2個ついています。一方で②最終選考のグラフには*が1個もつきませんでした。*の数だけに着目すると、最終選考では「問題解決力」を評価できなかったようにも受け取れます。本当にそうでしょうか?
①のグラフを見ると、1次選考合格者は「問題解決力」が平均7点以上の集団であったことが分かります。一般的な全国平均は5.5点のため、最終選考に参加した時点で「問題解決力」がかなり高い人に絞られていると推測できます。高得点の集団を2群に分けたため、2群間の差が表れにくくなってしまったと言えます。
②最終選考では*がつきませんでしたが、「問題解決力」の平均値は不合格者群よりも合格者群の方が高くなっています。「問題解決力」の評価という観点では、悪くない結果だったと解釈できます。
さいごに
今回取り上げた例のように、対象者が多いゆえにほとんどの尺度に*がついたり、選考が進むにつれて*がつく尺度が減っていったりする、という現象はよく見られます*がついている、ついていないという観点だけでは、その背景にある情報を見逃してしまう可能性があります。平均値の差の度合いや、平均得点などを見ることで、改めて得られる気づきもあるのです。 「タレントインサイト」という言葉をご存知ですか?タレントインサイトとは、採用から育成・配置・昇格などタレントマネジメント全般から得られるデータ活用とその知見を指します。
リアルタイムのタレントインサイトを効果的に活用できる人事チームは、より迅速かつ正確な人材に関する判断を行い、その結果、人材のポテンシャルを最大限に引き出すことができます。
人材データを活用して人事施策を進化させる方法については、白書やベストプラクティス、他社の成功事例など、様々な情報が溢れています。その多くは、「大規模な3年がかりのプロジェクトの成果」といったような大がかりな取り組みですが、実際には小規模な取り組みであっても意味のある変化を起こすことが可能です。
本コラムでは、人事機能のレベルアップのために何ができるかを検討している人事ご担当者向けに、SHLのタレントインサイト成熟度診断についてご紹介します。
タレントインサイト成熟度とは?
ある組織の採用からオンボーディング、能力開発や業績管理、そしてサクセッションプランまで全てを含めたタレントマネジメントの洗練度と有効性を評価するために使用されるもので、様々なモデルがあります。一般的に基礎から上級までいくつかのレベルに分かれており、高いレベルであるほどタレントマネジメントの取り組みが効果的で洗練されていることを示します。
SHLのタレントインサイト成熟度モデル
以下の5つのレベルに分かれています。- レベル1 旅の始まり:データが限られており、活用の余地が大きい
- あなたの組織は、人材データの活用が最小限にとどまっており、タレントアナリティクスの旅を始めたばかりです。妥当性のある人材データを収集することで、意思決定の質を大幅に向上させることができます。バイアス(偏見)を減らし、多様な人材のパイプラインを強化し、透明性のあるプロセスを促進することで、効果的な人材の維持、育成、昇進戦略が可能になります。
この段階では、取り組むべき領域や考慮すべき事項が多すぎて圧倒されるように感じるかもしれません。どの組織も、どこかの時点で経験したことなので心配しないでください。まずは最大の懸念点やリスクを1つ特定し、小さく始めましょう。自社の課題のリストを作成することをお勧めします。よくある問題意識の例を以下に挙げます。
取り組むべき課題を特定するのに支援が必要だとお感じになった場合には、ぜひ当社コンサルタントにご相談ください。- 将来のリーダーを準備するために、ハイポテンシャル人材の発掘・育成計画はあるか?
- 従業員に昇進やキャリア開発の機会を提供できているか?
- スキルギャップに対応するための人事戦略は何か?
- 現在組織内にどのような人材がいるか把握できているか?
- レベル2 戦略的に進める:データ活用に一貫性がなく、新たな優先課題が生じている
- あなたの組織は人材データの旅に乗り出しましたが、データの活用に一貫性がありません。優先的な課題は認識しているものの、組織全体でみるとデータ活用はまだ限定的です。
一般的に、アセスメントデータはハイポテンシャル人材の発掘や後継者育成などのより上級職務の意思決定に使用され、幅広い従業員層にはあまり使用されません。しかし、すべての従業員に能力開発と異動配置の機会を提供することで、定着率を高め、個人、ひいては組織のパフォーマンスを向上させることができます。
ここで主な障壁となるのは予算です。まずは客観的なデータを使った意思決定を行い、その結果どのように改善したか、影響を証明します。データ活用の価値とROIを証明できれば、組織の別階層への展開につながります。この次に重要なことは、組織内のあらゆるレベルにわたって大規模に人材ソリューションを提供でき、従業員のライフサイクルにおける全ての人事課題に対処するためにデータを再利用できるパートナーを見つけることです。
- レベル3 進捗を管理する:データ活用が組織内で別々に行われおり、統合の余地がある
- あなたの組織では、人材データは一貫して収集され利用されています。しかし多くの場合、別々に実施・保存されています。前進していることは明らかですが、より統合的で戦略的なアプローチはまだ手つかずのままです。このレベルでは、組織はアセスメントデータを客観的に収集するものの、その戦略的活用に苦慮していることが多いでしょう。
SHLの顧客の多くはこのレベルに該当します。次のステップは、既存の人材データを統合し、より総合的なアプローチに移行することです。特定の目的のために収集されたデータを、戦略的に複数の意思決定に活用しましょう。例えば、採用で収集したデータは、オンボーディング、能力開発、キャリアパスのサポートに再利用できます。また、アセスメントデータを上級職以外にも活用することを検討しましょう。ハイポテンシャル人材として認識されていない従業員を育成し、戦略的に再配置するためにデータを活用します。これには、データを保存し再利用できるプラットフォームが鍵となります。
- レベル4 優れた戦略を持つ:アセスメントがオペレーションの規範として統合されている
- あなたの組織は、人材データと分析の最前線にいます。人材に関する意思決定は客観的で妥当性のあるデータに基づいており、従業員のパフォーマンスと定着率は高まっています。このレベルの組織は、特定の目的のために個人データを収集し、目的に適うデータ活用を行います。質の高いデータが一つひとつの意思決定を支援し、組織の業績にプラスの影響を与えています。
次のステップは、集約された人材データの分析です。集団間の比較によって全体像を把握できるようになります。スキルギャップや多様性の問題、人材パイプラインの弱点の特定など、幅広くデータを活用する方法を検討しましょう。従業員の全体像を把握することで、事業戦略や環境の変化に合わせて機動的に行動できるようになります。つまりゴールポストが変わったときに、どのような影響があり、それに対して何をすべきかがわかるのです。
- レベル5 卓越している:タレントマネジメントが戦略的な事業運営の一部となっている
- あなたの組織は、客観的で妥当性のあるアセスメントデータを業務にシームレスに統合し、個人や組織全体のレベルで人材に関する意思決定に活用しています。この段階になると、複数の総合的な人材決定にデータを効果的に活用することができます。
タレントマネジメントを事業と同じように行うことで、業績向上や離職率の最小化など、大きなメリットが得られます。このような戦略的なアプローチにより、直近のニーズと将来の課題の両方に備えることができます。
課題はこの水準を維持することであり、そのためには継続的な評価と改善が重要です。テクノロジーと科学の進化に伴って、継続的な革新、投資、成長が必要です。タレントマネジメント施策の効果を追跡し続け、人材プロセスを改善し、組織外の専門知識も活用しましょう。

おわりに
SHLのタレントインサイト成熟度診断ツールは、画面に表示されるいくつかの質問にお答えいただくことで、ご自身の組織が上記5つのどのレベルに該当するかが分かります。まだ日本語版のご用意がありませんが、今後の人事組織改善のヒントをお探しの方はぜひ一度お試しください。
このシンポジウムのLIVE配信では、採用担当者である視聴者の皆さんに以下2点質問しました。
・前年と比較し、現在の内定受諾率は?
・26卒採用の検討事項として、関心が高いものは?
今回は、この視聴者アンケートから見えてきた各社の来期採用に向けた課題と、当社でご支援できる対応策について解説します。

25卒採用の現状と26卒採用に向けた課題とは?
シンポジウムのパネルディスカッション冒頭に回答いただいた、2つの質問の結果です。Q1.前年と比較し、現在の内定受諾率は?
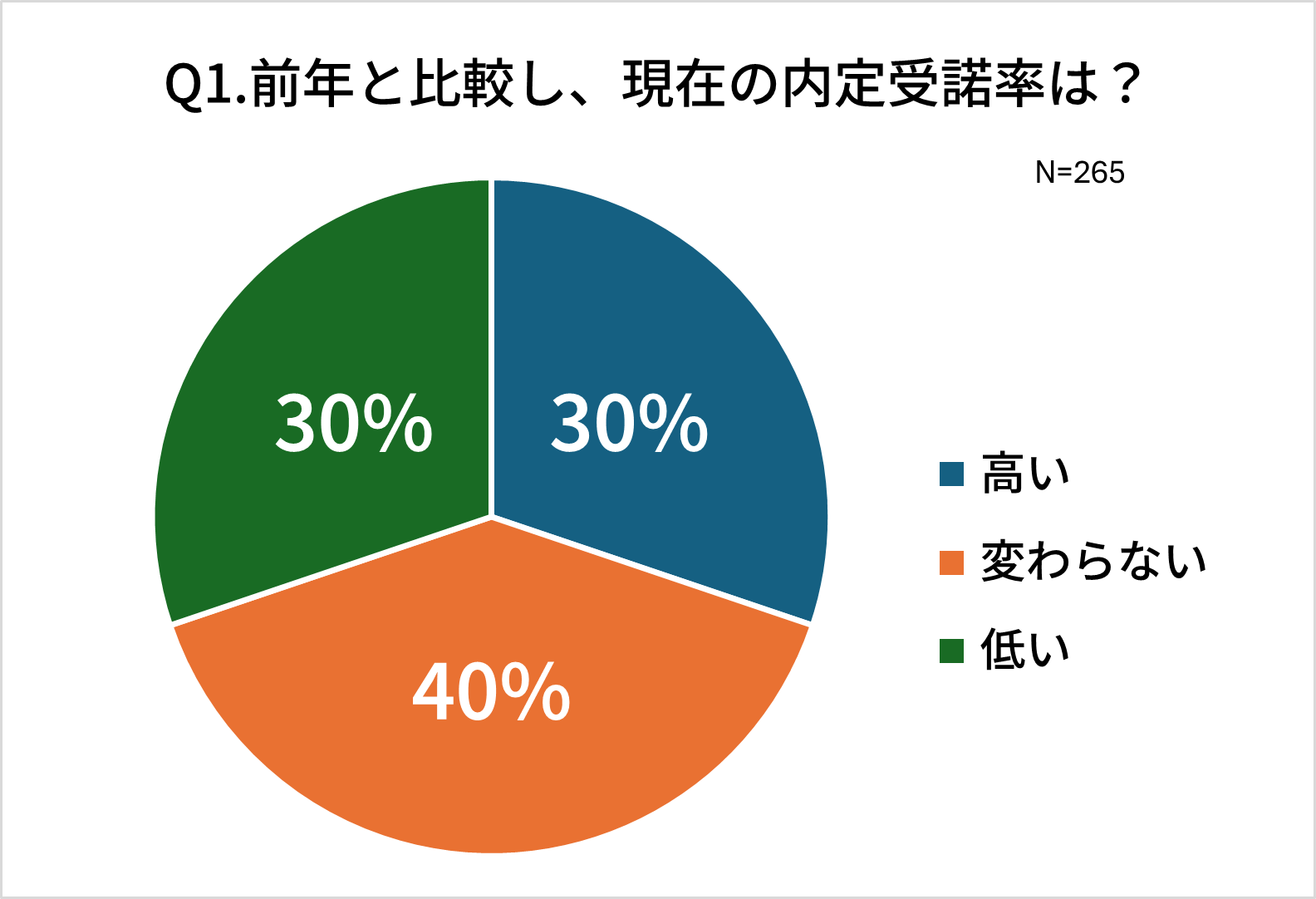
少子化と人材流動性の高まりを受けて、新卒採用が売り手市場と言われている昨今、早期に多くの学生が内定を持っていることが度々話題となっています。各社の実際の内定受諾状況はどうだったのか。回答は見事に分かれました。変わらないが全体の4割、高くなった/低くなったがまったく同じ30%。内定受諾率が世の中全体で特定の傾向を持っているとは捉えられませんでした。6月末時点での内定受諾率は各社各様であり、業界、企業規模、選考スケジュール等の様々な要素が影響しているだろうことが推測されます。
Q2. 26卒採用の検討事項として、関心が高いものは何ですか?
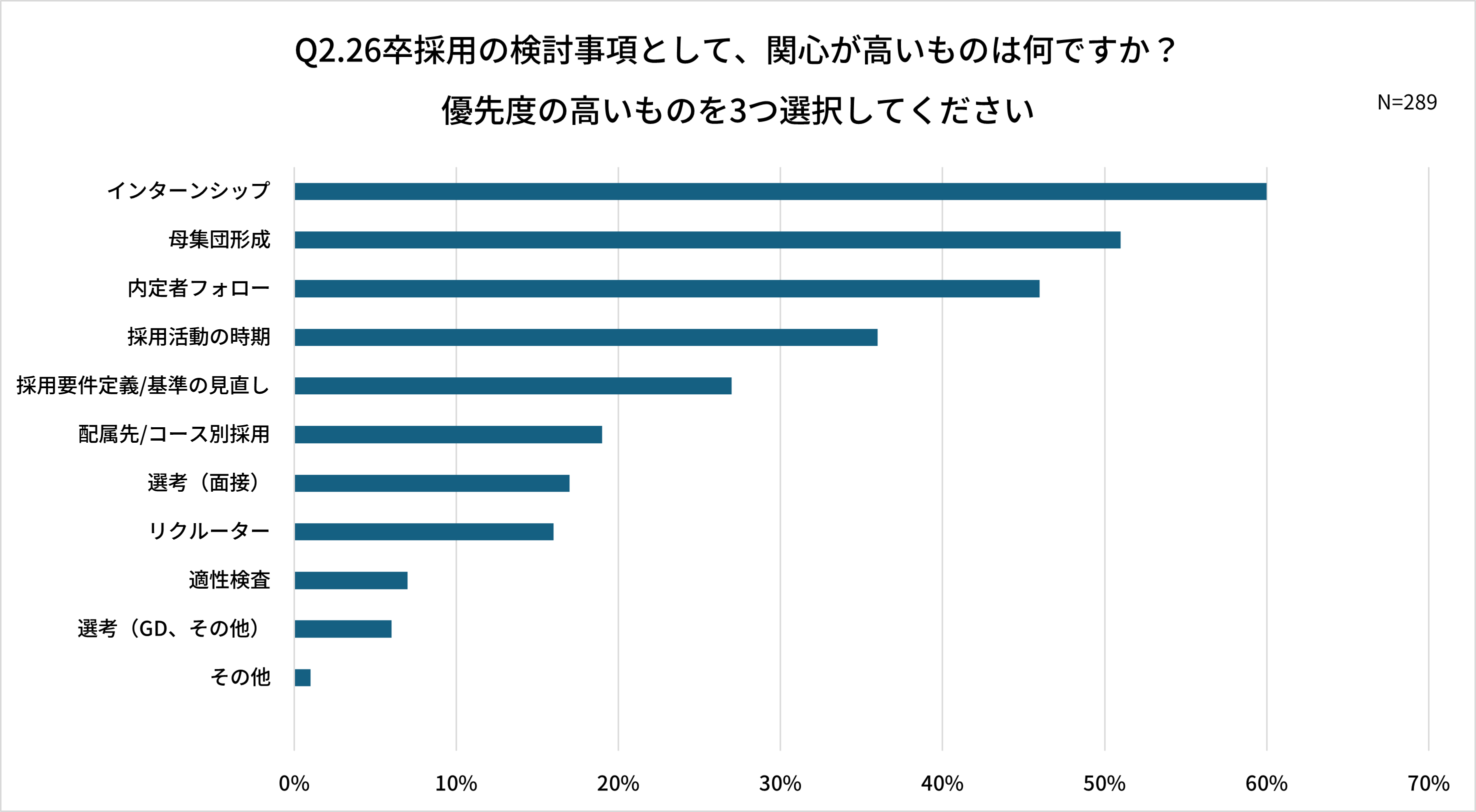
一方、来期に向けた課題は一定の傾向が見られました。関心事項の高い上位3項目はインターンシップ、母集団形成、内定者フォローでした。多くの学生と企業にとって最初の接点となるインターンシップ、そのインターンシップも含まれる母集団形成全般、そして工夫を重ねた末に確保した内定者を入社まで導くフォロー施策。採用活動の「始め」と「終わり」が特に課題として認識されており、まさに人材獲得競争の激化が背景にあることがうかがえます。
3つの課題と対処法
上位3つの関心事項は、アセスメントを主力とする当社事業は一見関係が薄いように見えるかもしれません。しかし、それぞれアセスメントの活用が可能です。- インターンシップ
- 採用選考は、ひと昔前の「企業が学生を選抜するもの」ではなくなっています。「選び選ばれる関係」「学生のキャリア観に寄り添う」といったキーワードがシンポジウムでも挙がりました。まさにこの考えに基づき、インターンシップは職務体験による仕事や会社理解を促す機会を提供しています。マッチングという観点では、企業側の情報を理解するだけでなく、応募者も自分自身を理解していることが重要です。自分はどんなことが得意で、何をしたいか。インターンシップの機会にOPQやV@W、MQなどを実施し、ぜひ学生にフィードバックしてあげてください。学生自身の行動特性、価値観、モチベーションリソースが可視化され、就職活動に大いに役立つことでしょう。加えて、自社の業務や組織風土などもうまく言語して、各種アセスメントの項目と結びつけながら解説することで、向いている人の背中を押し、またそうでない人のセルフスクリーニングを促す効果も期待できます。
- 母集団形成
- 人材獲得競争が激化している現状では、そもそも欲しい人材が応募してくれない、選考に進んでも辞退してしまう、という課題があるかもしれません。一見アセスメントでの解決が難しそうですが、改めて、この「欲しい人材」を見直すことが母集団形成における課題解決の糸口になるかもしれません。画一的な人物像が採用活動において機能しなくなっているのであれば、人材像をスキルベースで定義するのも一手です。人物像をスキルに分解することで、これまでターゲットとみなしていなかった集団が特定のスキルを持つ新たなターゲットになるかもしれません。今までの型にあてはまらない人たち、取りこぼしていた人たちを見直し、新たな母集団形成につなげられる可能性を秘めています。仕事に必要なスキル、応募者のスキルの可視化はアセスメントが活用できます。
- 内定者フォロー
- 内定後、入社までの期間も継続的な「相互理解」の機会が必要です。インターンシップの対応策でご紹介した、各種アセスメントでの自己理解促進はこの場面でも役に立ちます。さらに、細やかなフォローをするために、リクルーターや先輩社員との相性を各種アセスメントから予測することも可能です。相性の考え方は大きく2つあります。「①自分と似たコミュニケーションをとる」、「②自分と相互補完的な特徴を持つ」です。 実施にあたって、学生と面談する社員やリクルーターに事前にOPQを受検してもらいます。学生のアセスメント結果から、希望する職種やキャリア、性別など属性情報のほか、個人特性の相性もふまえて、より個別的なコミュニケーションが可能になります。

おわりに
25卒の採用選考が続いている中、すでに多くの企業が来期の採用に向けても計画を進めています。他ではなかなか聞けない各社の事例とともに、本コラムが採用活動の改善のヒントになれば幸いです。 人的資本経営というキーワードとともに、近年、人材データやピープルアナリティクスがさらに注目されています。人材データとは具体的にどんな情報を用いるか?データをどのように活用すべきか?分析手法とはなにか?その際の注意点とは?・・・データ分析にまつまる様々な疑問をお持ちの皆さんに、今回は当サイトでこれまで取り上げたデータ分析やピープルアナリティクスに関する知見やベストプラクティスをまとめてご紹介します。人材データ分析、ピープルアナリティクス、人材ポートフォリオなどにご関心のある方はぜひご覧ください。
人材データ分析に関するお役立ちコラム
データ分析の基礎知識:
分析手法の知見:
データ分析のヒント:
- ピープルアナリティクスを進める時に注意したい3つのポイント
- 少ないデータでもできる人材可視化の手法
- 意味のある統計分析を行うために必要な「目的の明確化」
- データ分析における主観性と客観性 ~シンプソンのパラドックスとデータ・インフォームド~

人材データ分析お役立ちダウンロード資料
各社の人材データ分析に関する事例
各社の人材データ分析や人材可視化に関するお取り組みをインタビューや事例でご紹介しています。タレントマネジメント
- 森永乳業の適材採用・適材配置を加速させた日本エス・エイチ・エルのアセスメント
- 急成長するLAVA Internationalの科学的人事戦略。
- 「人の目だけに頼る人事」を脱却する、理想科学工業の人材可視化プロジェクト。
- 求める管理職像を明らかにする。メディアフォースの人材開発プロジェクト
- 事業ポートフォリオの転換を支えるゲオホールディングスの活躍店長タイプ分析
- 社員の行動特性可視化によって科学的根拠に基づく採用と人財活用を実現した日揮ホールディングス
- 松屋フーズ、「牛めし」の次の柱を作る新事業人材の発掘
- タレントマネジメントシステム×適性検査データの広範的活用。ブラザー販売の人材可視化プロジェクト。
- 複線型キャリアと絶対評価によるスペシャリスト育成。業界をリードする高度ソフトウェアエンジニア集団を目指すデンソークリエイトの人事制度改革。
- 工場設備保全員の安全管理にアセスメントを活用。日産自動車横浜工場の挑戦。
育成
- ジェイテクトのグローバル経営をけん引する強い経営人材の選抜と育成
- 「自分に合ったスタイル」での成長を促す、日産自動車の販売会社店長育成戦略。
- 1on1ミーティングにおけるアセスメント活用でコーチングを推進。朝日インテックJセールスの事例。
- ソフトウェア技術者へリスキリング。デンソーの「キャリア転進プログラム」
- サステナブルな事業展開のために、社員のキャリア自律を促すサントリーフラワーズの挑戦。
- 管理職候補者への動機づけとマネジメント教育を担う、大塚商会のリーダー育成プログラム「リーダーカレッジ」。
採用
- 三井物産の「科学的採用」を支えた日本エス・エイチ・エルのアセスメント
- オンライン選考を有効なものにした、日立ビルシステムの採用基準作成。
- ブレークスルーを起こせる人材求む。ファイザーの人材要件定義プロジェクト。
- 船乗りの適性を見える化。商船三井の海上職採用要件定義プロジェクト。
- 学力テストから適性テストへ。「くもんの先生」としての活躍の可能性を見極める、公文教育研究会の採用改革。
- 採用から育成まで一本筋を通すイムラ封筒の人材要件定義